🚩 BKSEC - Maze Maze Mazeeee
Primary: 01 - Web Security
Secondary: 02 - Enumeration
Executive Summary
- IP:
http://103.77.175.40:8031 - Key Technique: Enumeration robots.txt into writing automation script for exploit.
- Status:
Completed
Reconnaissance
Web Enumeration
The page served a static home page that has an <h1> element saying “ARE YOU ROBOT?”, inspecting the page gives me know that the title of this page is called Maze Entrance.
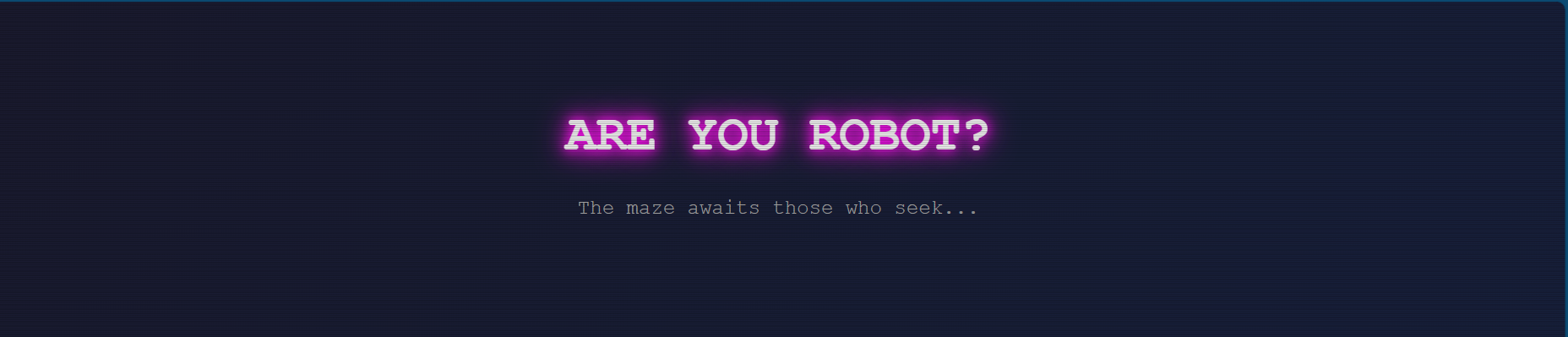
I instinctively know this might be a hint for me to check out the page’s robots.txt file (which is a page that was normally made as a guideline for search engines’ bots or crawlers). Thankfully the file exists and can be access.
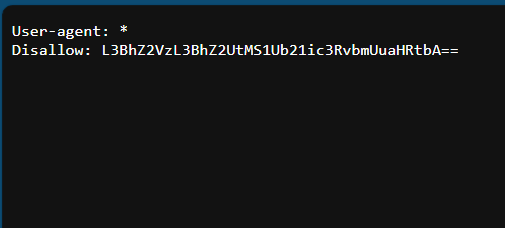
There was a base64 encoded string L3BhZ2VzL3BhZ2UtMS1Ub21ic3RvbmUuaHRtbA== decoded to be /pages/page-1-Tombstone.html
Following the link I got to things that seems to be the real content of this challenge which is a page filled with colored rectangle:

I tried clicking on one of the rectangle but nothing happened. Then I inspect the page:
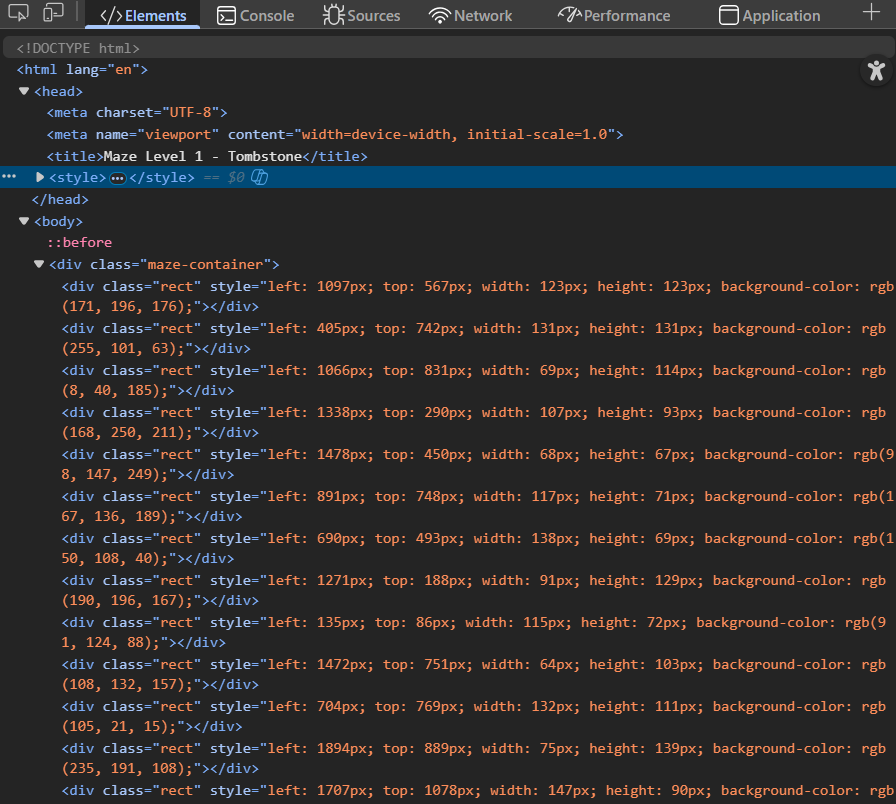
There is the title, and hundreds of rectangle elements inside maze-container element. I check out the cookie but seems like the page does not uses cookie. To find out more about what I need to do, I open BurpSuite but nothing notable was found.
Then I tried asking Gemini for the challenge and it suggested me to find a rectangle that contains a link to next challenge (aka. one that contain an <a> tag)
Looking at the response I got from Burpsuite and look for an <a> tag, there is indeed one single tag existed.
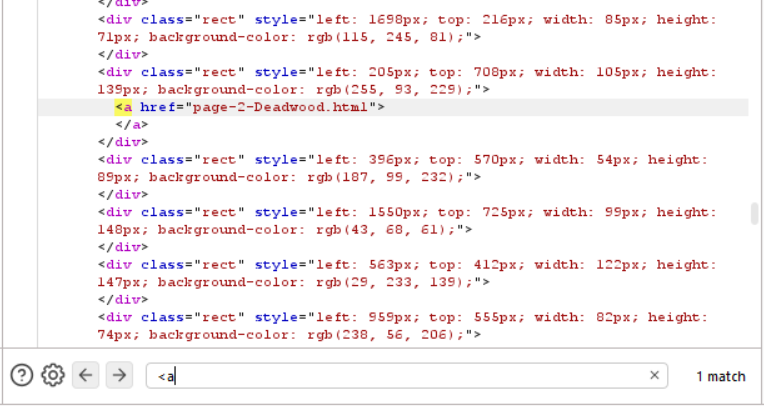
Round 1: Find the <a> tag
I saw the way and starts repeatedly doing the same thing as finding the <a> tag for about 20 times, and I realized maybe there can be hundreds of such levels, doing it manually would takes tremendous time. So I decide to write a script to navigate through the challenge.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import sys
current_url = "http://103.77.175.40:8031/pages/page-1-Tombstone.html"
while True:
print(f"Checking: {current_url}")
try:
response = requests.get(current_url)
page_content = response.text
if "BKSEC{" in page_content:
print("flag at:" + current_url)
break
soup = BeautifulSoup(page_content, 'html.parser')
link_tag = soup.select_one('.rect a')
relative_link = link_tag.get('href')
next_url = urljoin(current_url, relative_link)
current_url = next_url
except Exception as e:
print(f"ERROR: {e}")
breakThe code did not return a flag but stopped at level 101, when I entered the page at that level there is a button that leads to a second round.
Checking: http://103.77.175.40:8031/pages/page-96-Avra_Valley.html
Checking: http://103.77.175.40:8031/pages/page-97-Altar_Valley.html
Checking: http://103.77.175.40:8031/pages/page-98-San_Rafael_Valley.html
Checking: http://103.77.175.40:8031/pages/page-99-Sonoita_Valley.html
Checking: http://103.77.175.40:8031/pages/page-100-Sulphur_Springs_Valley.html
Checking: http://103.77.175.40:8031/pages/page-101-qncdl1248dbsl.html
ERROR: 'NoneType' object has no attribute 'get'
Round 2: Find the flag.
Clicking on the PROCEED TO ROUND 2 led me to a webpage that was format like a file system, where there were folders and files. Clicking on the folder led me to the index.html file of the directory of that folder, which had the same system file interface. For example:
/round2_qncdl1248dbsl/index.html(parent) →/round2_qncdl1248dbsl/giftsgssul/index.html
Clicking on the html file (all files were html apparently) leads me to the html file of the same directory.
/round2_qncdl1248dbsl/index.html→/round2_qncdl1248dbsl/dnvgzrekzl.html
The I wrote a script using simple BFS:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from collections import deque
start_url = "http://103.77.175.40:8031/round2_qncdl1248dbsl/index.html"
s = requests.Session()
queue = deque([start_url])
visited = set([start_url])
while queue:
current_url = queue.popleft()
try:
response = s.get(current_url, timeout=10)
page_content = response.text
if "BKSEC{" in page_content:
print(f"Flag at: {current_url}")
break
soup = BeautifulSoup(page_content, 'html.parser')
links = soup.select('.directory-list a')
for link in links:
href = link.get('href')
next_url = urljoin(current_url, href)
if next_url not in visited:
visited.add(next_url)
queue.append(next_url)
except Exception as e:
print(f"ERROR: {e}")
passThe code returned one link to a fake flag. There could be more than one fake flag so I decided to modify the code so that printed every flag:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from collections import deque
import re
START_URL = "http://103.77.175.40:8031/round2_qncdl1248dbsl/index.html"
s = requests.Session()
queue = deque([START_URL])
visited = set([START_URL])
while queue:
url = queue.popleft()
try:
response = s.get(url, timeout=10)
page_content = response.text
match = re.search(r"BKSEC\{.*?\}", page_content)
if match:
print(f"Flag: {match.group(0)}")
soup = BeautifulSoup(page_content, 'html.parser')
links = soup.select('.directory-list a')
for link in links:
href = link.get('href')
full_url = urljoin(url, href)
if full_url not in visited:
visited.add(full_url)
queue.append(full_url)
except Exception as e:
print(f"ERROR: {e}")
passThe result that had the real flag:

Loot & Flags
Flag: BKSEC{f4st_runn3r_f4st_runn3r_f1a9c4!!!!!!!!}